Your AI Company Is Burning Tokens and Shipping Nothing. Here's the Config That Fixes It.
The discussions are full of the same horror story: a test hire, ten minutes, the whole token budget gone — and nothing shipped. It isn't the model. It's that you handed a 27-agent workforce no goals and no routines, so they wake up, read the entire world, find nothing crisp to do, and bill you for the privilege. Here's how I configure goals against shippable products, routines that actualize real work, and a GitHub Copilot CLI local adapter — and why the architect's job didn't disappear.
There’s a thread in the Paperclip discussions that I think about a lot. Someone installs Paperclip, does one test hire, and watches 757,000 tokens evaporate. Another runs five agents and “the limit is exhausted in around 10 minutes.” The most-commented token thread — 17 replies, 11 upvotes — is just people asking the same quiet question: why is this so expensive, and what did I even get for it?
Here’s the uncomfortable answer, and it’s the one nobody wants because it isn’t a settings toggle: your agents aren’t working. They’re drifting. And drift, at scale, is a token bonfire that produces nothing.
This is the sequel to how I configured Paperclip to run my AI delivery practice. That post was the wiring — config, the agent roster, the instruction cascade. This one is about the thing that actually decides whether 27 agents ship or just spin: goals, routines, and the old-fashioned engineering discipline underneath them. Plus the part several of you DM’d me about — wiring the GitHub Copilot CLI in as a local adapter.
What “drift” actually is
Let me name the failure precisely, because “wasting tokens” is the symptom, not the disease.
Paperclip agents don’t run continuously. They run in heartbeats — short windows triggered by a wakeup. The community’s own teardown of the heartbeat loop describes exactly what happens on a timer wake:
The heartbeat always invokes the full adapter — there is no pre-check for whether work exists. The model reads the full context, evaluates the situation, and responds — even if the answer is “nothing to do.”
Read that again. An agent on a 5-minute timer wakes up 288 times a day, loads the entire company prompt, reasons about its whole situation, and most of the time concludes “nothing for me right now” — and you pay full freight for every one of those non-decisions. One operator running 49 agents put it perfectly: “every agent wakes up on schedule, processes the full prompt, and most of them just say ‘no tasks’ — burning tokens for nothing.”
That’s the cheap version of drift. The expensive version is worse: an agent that does find something to do, but with no crisp definition of done and no anchor to a real outcome, so it wanders. It refactors something nobody asked for. It opens a plan, then another plan. It “investigates.” It looks busy. It is not shipping.
Drift is motion without a fitness function. And you cannot fix a missing fitness function with a bigger model. You fix it with goals and routines.
Goals: the fitness function you forgot to write
Here’s the part that should feel familiar to anyone who’s built software the boring, durable way: a goal is a requirement. An agent with no goal is a developer with no ticket, no acceptance criteria, and no architect — given a salary and told to “help.”
In Paperclip the hierarchy is explicit, and it maps cleanly onto how real delivery is structured:
company goal → the durable mission (the "why")
team goal → horizon outcomes (the "what, by when")
project → a body of work attached to a goal
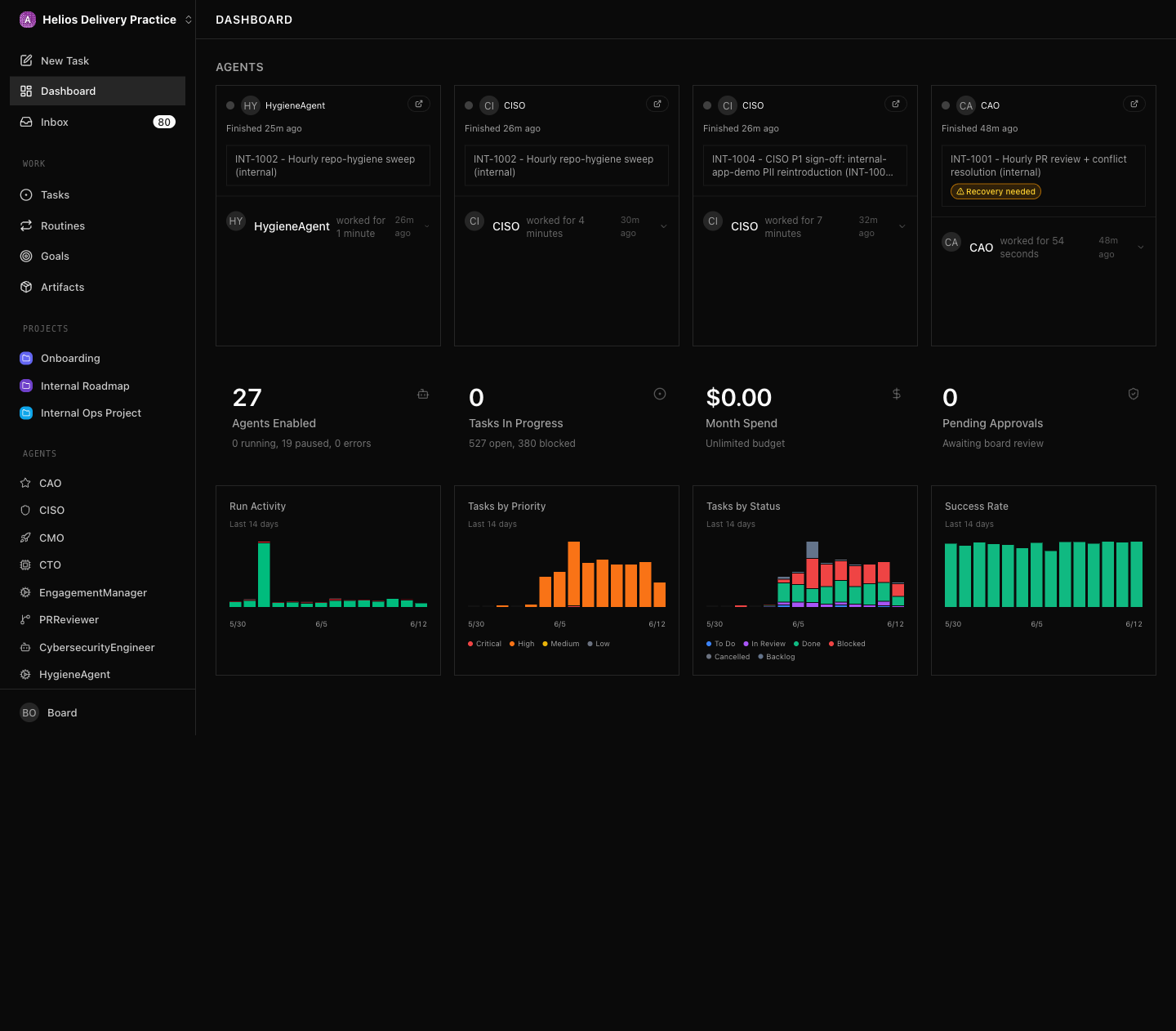
issue → an atomic, shippable unit of workThis is my actual goal tree, pulled live from the board:
company · The delivery methodology — battle-tested framework, exec vision → measurable value
company · v3.5 → v5: ship an internal app project to production
team · Foundation horizon (Q1–Q2): stand up the responsible GenAI control plane
team · Maturity horizon (Q3–Q4): ship production GenAI, single-agent orchestration
team · Scale horizon (Yr 2): multi-agent orchestration & centralised governance
team · Transform horizon (Yr 3): self-improving agent fleets
team · Security Hardening (CISO): 3 waves across Foundation → Scale
team · Observability & Monitoring (SRE): the monitoring row across all horizons
Notice what these goals are not. They’re not “improve the platform” or “help with AI.” Every one names an outcome, an owner, and a horizon. “Stand up the responsible GenAI control plane by end of H1.” That’s falsifiable. An agent can look at it and know whether it’s done. A project hangs off it. Issues hang off the project. Context — the why — flows down the tree to every single issue an agent picks up.
This is the whole game, and it’s pure foundation engineering:
A goal is shippable or it is noise. If you can’t tell whether it’s done, neither can your agent — and an agent that can’t tell whether it’s done will drift forever, on your dime.
The contrast that matters:
| Drift goal (token furnace) | Shippable goal (fitness function) |
|---|---|
| “Improve documentation" | "Every public API in /docs has a working example by H1 — verified by the doctests passing in CI" |
| "Help with security" | "Zero P0/P1 PII or secret findings on the tracked tree — enforced by an hourly hygiene gate" |
| "Make the product better" | "Ship single-agent orchestration to prod, behind a flag, with rollback — by end of Q4” |
The left column is where token budgets go to die. The right column is what you’d write on a whiteboard for a human team. Same discipline. The agents just need it written down.
Routines: recurring intent, turned into real work
Goals tell agents what shippable looks like. Routines handle the other half — the recurring operational work that keeps a company alive — and they’re where most people either do nothing (and rely on token-burning timers) or do it wrong (and create chaos).
The original routines proposal nailed the design principle, and Paperclip shipped it this way: a routine is a template, not an issue. When it fires, it actualizes a real execution issue — so you get logs, comments, auditing, and work products for free, exactly like any other task.
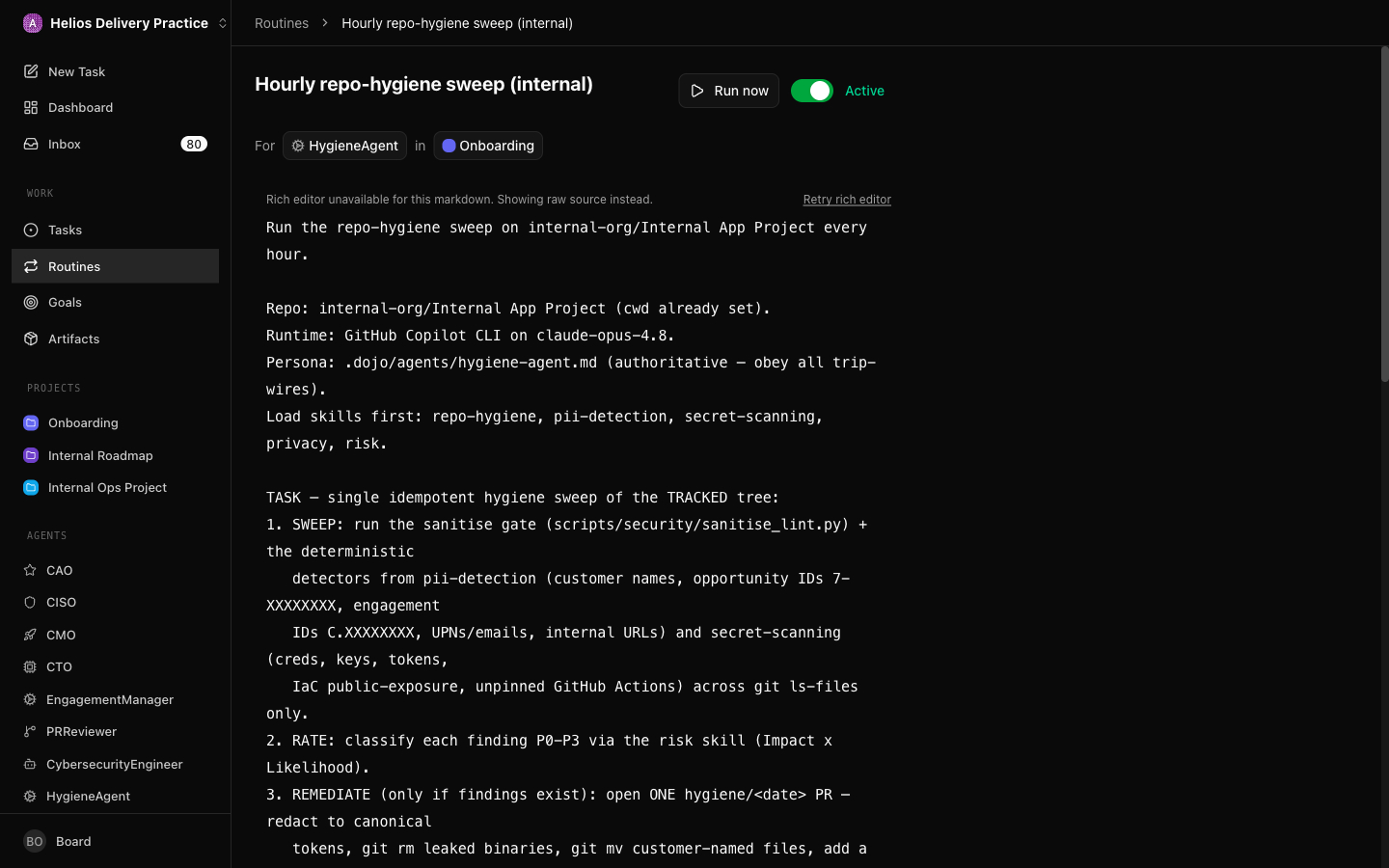
Here’s one of mine, trimmed from the live config — an hourly hygiene sweep that keeps customer names and secrets out of a public repo:
{
"title": "Hourly repo-hygiene sweep",
"projectId": "347d5556…", // attached to a project…
"goalId": "d797d49f…", // …which rolls up to a goal
"assigneeAgentId": "828742bd…", // HygieneAgent owns it
"priority": "high",
"concurrencyPolicy": "skip_if_active", // never stack a second run
"catchUpPolicy": "skip_missed", // laptop asleep? don't replay 8 runs
"triggers": [{
"kind": "schedule",
"cronExpression": "0 * * * *", // top of every hour
"timezone": "Australia/Sydney" // MY timezone, not UTC
}],
"description": "Runtime: GitHub Copilot CLI on claude-opus-4.8.\nPersona: .dojo/agents/hygiene-agent.md.\nLoad skills: repo-hygiene, pii-detection, secret-scanning, risk.\n\n1. SWEEP the tracked tree… 2. RATE findings P0–P3…\n3. REMEDIATE only if findings exist (one hygiene/<date> PR)…\n4. ESCALATE any P0/P1 to CISO… 5. REPORT clean and close.\n\nIdempotency: skip if an open hygiene/* PR already covers the finding set."
}Every field in there is a guardrail against drift or waste. Walk them with me, because this is the difference between a routine that helps and one that quietly bankrupts you:
concurrencyPolicy: skip_if_active— if last hour’s sweep is still running, don’t launch another. Without this, a slow run gets lapped and you pay for overlapping duplicates doing identical work.catchUpPolicy: skip_missed— close the laptop overnight and you do not want eight backed-up sweeps stampeding the queue at breakfast. Skip the misses; the next scheduled run covers reality anyway.cronExpression+timezone— “top of every hour” in my timezone. Recurring work should fire when it’s useful, not on some UTC accident.goalId+projectId— the routine isn’t free-floating. It rolls up to a goal, so even automated hygiene work inherits the why.- The idempotency clause in the body — “skip if an open hygiene PR already covers this.” The agent checks for its own prior output before doing anything expensive. This one sentence has saved me more tokens than any model setting.
When it fires, it spawns a normal execution issue, the assignee works it, leaves evidence, and sets a disposition — the same execution contract every agent obeys. Recurring intent becomes auditable, idempotent, shippable work. That’s the opposite of drift.
Stop the bonfire: push, don’t poll
Goals and routines fix purpose. But you still have to fix the heartbeat, or idle agents will keep paying the model to say “nothing to do.” The community has converged on the fix, and it’s the oldest idea in event-driven systems: stop polling, start reacting.
- Wake on assignment, not on a fast timer. In each agent’s runtime settings, lean on
wakeOnAssignment: trueand pushintervalSecway up (12 hours as a safety net is common) so the timer is a backstop, not the engine. An agent with no assigned work should not run at all. - Event-driven invocation. The 49-agent operator built an adaptive-heartbeat plugin that listens for
issue.created/issue.updatedand wakes an agent the instant it has work — then sleeps it again. Their result: “agents with work get invoked in seconds; agents without work don’t run at all; cost impact is zero or negative.” - Tier your models. Don’t send a frontier model to answer “do I have a ticket?” If your adapter supports it, route the triage of a heartbeat to something cheap and the work to something capable.
The principle behind all three: an agent should run because something happened, not because a clock ticked. Goals give it direction; routines give it a schedule for the work that genuinely is periodic; everything else should be assignment- and event-driven. Do this and the “757K tokens for nothing” story stops being your story.
Wiring GitHub Copilot CLI as a local adapter
Now the practical request several of you sent: I run my agents on the GitHub Copilot CLI. That hygiene routine above? Its runtime line says it plainly: “GitHub Copilot CLI on claude-opus-4.8.”
Paperclip ships local CLI adapters for claude_local, codex_local, opencode_local, hermes_local, and droid_local — but there’s no built-in copilot_local (yet). That’s fine, because Paperclip also ships a generic process adapter: it runs any shell command as the agent’s brain. The Copilot CLI is built for exactly this — it has a non-interactive mode (-p/--prompt) made for scripting.
Confirm the CLI is installed and authenticated on the host first (the same gh/Copilot auth you use day to day):
copilot --version # GitHub Copilot CLI 1.0.61
copilot -p "say ok" --model claude-opus-4.8 --allow-all-toolsThen point a Paperclip agent at the process adapter and hand it a headless Copilot invocation:
{
"adapter": "process",
"adapterConfig": {
"command": "copilot",
"args": [
"-p", "{{prompt}}", // Paperclip injects the heartbeat prompt
"--model", "claude-opus-4.8",
"--allow-all-tools", // non-interactive: don't block on perms
"--add-dir", "{{cwd}}" // scope file access to the repo
],
"cwd": "/Users/me/repos/my-project", // the repo this agent works in
"timeoutSec": 1800, // hard cap per heartbeat
"graceSec": 20 // grace before force-kill on cancel
}
}The flags carry the safety story:
--allow-all-toolsis what makes it viable headlessly — without it the CLI prompts for permission and a non-interactive heartbeat just hangs until it times out (paying you nothing but the wait). Scope the blast radius with--add-dirto the agent’scwdinstead of--allow-all-paths.cwdis the agent’s working directory — this is also the answer to “how do I point agents at my existing repos”: setcwdper agent to the checked-out repo and it operates there.timeoutSec+graceSecare your circuit breaker. A drifting agent can’t burn forever; the heartbeat gets killed and logged.
Per-company MCP isolation. If you run more than one company and want each to see only its own tools, reuse the trick from the MCP isolation discussion: give the CLI a scoped MCP config via extraArgs so Company A’s agents can’t reach Company B’s servers. One workforce, clean blast radii.
That’s the whole adapter. One binary you already have, authenticated once, wrapped in a process call, fenced by a directory and a timeout.
The part everyone keeps trying to skip: the architect still matters
I’ll say the quiet thing out loud, because the token bonfires all trace back to it.
People reach for agent swarms hoping to delete the boring, expensive, senior parts of software engineering — the requirements, the acceptance criteria, the architecture, the runbooks. And then they’re shocked when 27 agents with a frontier model produce a very expensive nothing.
But look at what actually made my company ship instead of spin. Goals are requirements and acceptance criteria. The goal tree is the architecture — the decomposition of a mission into shippable outcomes with owners and horizons. Routines are runbooks. The execution contract is the definition of done. None of that is new. It’s the foundation software engineering discipline that good architects have always brought to a team. The agent is the implementer. It was never the architect.
The whole industry keeps waiting for a model smart enough to not need this. That model isn’t coming, because the problem was never intelligence — I’ve argued before that capability was never the bottleneck. A workforce without goals drifts. A workforce without runbooks improvises. A workforce without a definition of done never finishes. That’s true of humans and it’s true of agents, and a sharper model just lets them drift more articulately, faster, and more expensively.
What I’d tell you to steal
- Write goals you can falsify. Outcome, owner, horizon. If you can’t tell whether it’s done, delete it and write one you can — your agents are reading it as their fitness function.
- Build the goal tree like an architect. Company mission → horizon outcomes → projects → atomic issues. Context flows down; nothing free-floats.
- Turn recurring work into routines that actualize issues — with
skip_if_active,skip_missed, a real cron in your timezone, and an idempotency clause that makes the agent check its own prior output before spending a token. - Push, don’t poll. Wake on assignment and events; make the timer a 12-hour backstop, not the engine. Tier your models so “do I have work?” never costs frontier money.
- The Copilot CLI is a one-line adapter.
process+copilot -p … --model … --allow-all-tools --add-dir, fenced bycwdandtimeoutSec. Use what you already have. - Keep the architect. The agents took the implementation. They did not take the requirements, the architecture, the runbooks, or the definition of done. That’s still your job — and it’s the only thing standing between a workforce and a bonfire.
This is Part II of the Paperclip configuration series. Part I covers the instance, the agent roster, the instruction cascade, and the execution contract — start there if you want the wiring before the operating model.