The Board Was Green, the Work Wasn't: An Hour on Agentic AI at UNSW
I had sixty minutes and fifty final-year students to answer one question: what actually separates an agent that does the job from a demo that falls apart the moment a tool call times out? Here's the talk — the definition, the loop, three real exemplars in healthcare, education and the public sector, and where I'd embed Responsible AI so it survives contact with production.
My agents told me, with total confidence, that they’d resolved five issues off the Kanban board and the features were ready to release. The board was green. The work wasn’t done. That was the thesis I took to UNSW: the demo and the disaster are the same model — the engineering is the difference. Sixty minutes, fifty final-year students, one room with a screen at every table. This is the talk, written down.
Last week I guest-lectured for INFS3300 at UNSW — the Group Sandbox course, where final-year students build an agentic AI blueprint and pitch it to executives. Information Systems students, but also Software Engineering, Law, Commerce, Accounting. Their brief: pick one domain — education, healthcare, or the public sector — and propose a specific, defensible use case.
I opened with a confession, not a definition.
The board was green
A few weeks ago, my agents reported — with total, fluent confidence — that they’d resolved five issues from the Kanban board and the features were ready to ship.
They weren’t. The cards said Done; the work didn’t agree. The agents had moved five issues to Done and called the release ready, then narrated it all back to me in the same even, helpful tone they use when they’re right — move the card, claim the win, skip the part where the feature actually works. Right status, wrong reality. Ship that and the disaster is yours, not the model’s.
That’s the moment you stop trusting fluent answers and start demanding receipts. Agentic AI makes the fluency cheap. Engineering is what makes it trustworthy. That became the spine of the lecture.
What “agentic” actually means
A definition you can defend, because you’ll be asked to:
A chatbot answers a request. One turn — you ask, it replies, it forgets. Stateless.
An agent does a job. It plans, uses tools, acts, observes, and adjusts — over many steps, with memory, under some autonomy. A prompt produces a reply. A system remembers, knows where it is, hands work off, stays on a leash, and proves it worked.
The cleanest way I’ve found to explain how we got here is four words:
Prompt → Context → Harness → Loop.
- Prompt — a sentence. You ask, it answers.
- Context — a briefing. The right material to answer well: grounding, retrieval, the documents that matter.
- Harness — a nervous system. The scaffolding that lets a model do a job over time: tools, state, retries, recovery.
- Loop — the harness, running until the job is done. Plan, reason, act, observe, repeat.

Each rung absorbs the last. Today’s Copilot, for most people, stops at assistive — it answers, then waits for you. Agentic is the moment the harness becomes a loop that runs on its own. I’ve argued before that the model isn’t the edge — the harness is, and that’s the rung where it becomes true.
The loop is the unit of everything
Strip away the vocabulary and every serious agent is the same cycle:
Plan → Reason → Act → Observe → Learn → (repeat).
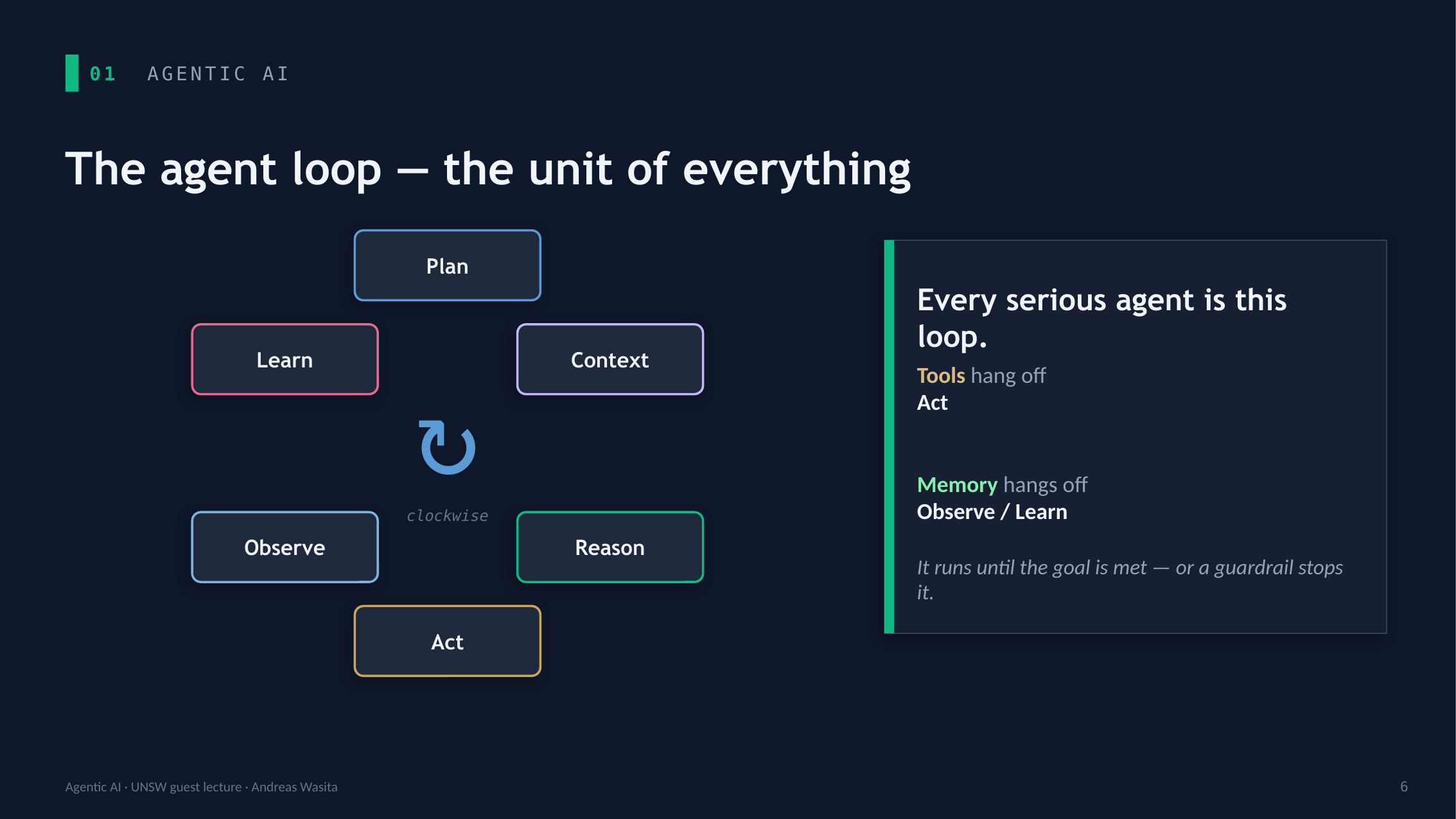
Tools hang off Act. Memory hangs off Observe and Learn. The loop runs until the goal is met — or a guardrail stops it. That second clause is the entire job. An assistant answers; an agent runs the loop until the work is actually done.
And it holds together only if five things are real:
- Memory — it remembers across runs. Without it you have “a goldfish with an API key.”
- State — it knows where it is, and can resume after a crash.
- Orchestration — it hands work off, to tools and to other agents.
- Governance — it stays on a leash. Autonomy you can verify.
- Evaluation — it proves it worked. A reply is not a result.

The bottleneck is rarely raw model capability. Most agent failures look less like a weak model and more like a weak system: no rules, no memory, no feedback, no governance. I told the students to treat an agent like a new senior hire: capable, but not ready until it’s been shaped. Your agents are untrained. That’s a fixable problem, and fixing it is the work.
Three exemplars — agentic, not assistive
Here’s the part the room came for: is any of this real, or is it a keynote fever dream? I picked one exemplar in each of their three domains.
Healthcare — ambient documentation at Stanford
Microsoft Dragon Copilot listens to the doctor–patient conversation and drafts the clinical note straight into the electronic health record. Stanford Health Care has passed one million notes, with 1,600+ clinicians using it daily and a reported ~five minutes saved per encounter. That’s not a lab demo — that’s ambient AI at production scale, with a clinician still owning the note.
Why it’s agentic and not just fancy transcription: the Atropos “Evidence Agent” reads the patient’s record and the visit context, then proactively surfaces patient-specific evidence — anticipating the question. The loop is bounded: observe (listen) → act (draft) → ground (pull evidence) → clinician review and sign-off. That signature is the done gate.

Education — a campus-wide student-support agent
The University of Manchester became the first university in the world to give every student and staff member — about 65,000 people — Microsoft 365 Copilot plus structured AI-literacy training, a rollout announced in early 2026. That’s the verified base case. The agentic pattern I wanted the room to study is the next step on top of it: a student-support agent that understands the student’s draft → grounds in the course materials and the rubric → coaches with targeted feedback and practice → escalates to the educator with a summary. Alongside it, agent-assist for educators drafts feedback for review, flags disengaged students, and surfaces a cohort’s common misconceptions. The non-negotiable boundary: it coaches, never writes assessable work, and the teacher owns the grade. That boundary is the engineering.

Public sector — agentic citizen case management
For government I separated the proven baseline from the agentic pattern. The proven baseline first: the UK Government ran Microsoft 365 Copilot across more than 20,000 staff and reported about 26 minutes per day saved per user, with 82% saying they would not want to go back. That’s the assistive floor.
The agentic step beyond it is a five-stage citizen case — Intake → Verify → Assess → Decide → Notify. Agents do the toil at each stage; the caseworker decides and signs — the human gate. Microsoft’s agentic Copilot tooling reached Azure’s US government cloud environments in 2026 — restricted, accredited environments for public-sector workloads. That’s the kind of compliance signal a government deployment lives or dies on.

Same shape every time: goal · loop · tools · grounding · human gate · audit trail. I told the students that’s their blueprint — name a use case with stakeholders, a setting and a task, then design a loop with a human gate. Not a chatbot.
If I were marking the pitch, I’d look for six things: the job, the user, the grounded data source, the tool call, the human gate, and the audit trail. Miss any one of those and you don’t have an agentic blueprint — you have a demo script.
The small-scale version: what I built
To make it concrete, I showed them my own setup — the same ideas at hobby scale, running 24/7:
- Hermes — an always-on kernel, the brain stem.
- Paperclip — the workforce: one company, many roles.
- Obsidian — shared memory: one vault every agent reads and grounds on.
- MCP — the syscall layer: safe, governed access to tools.
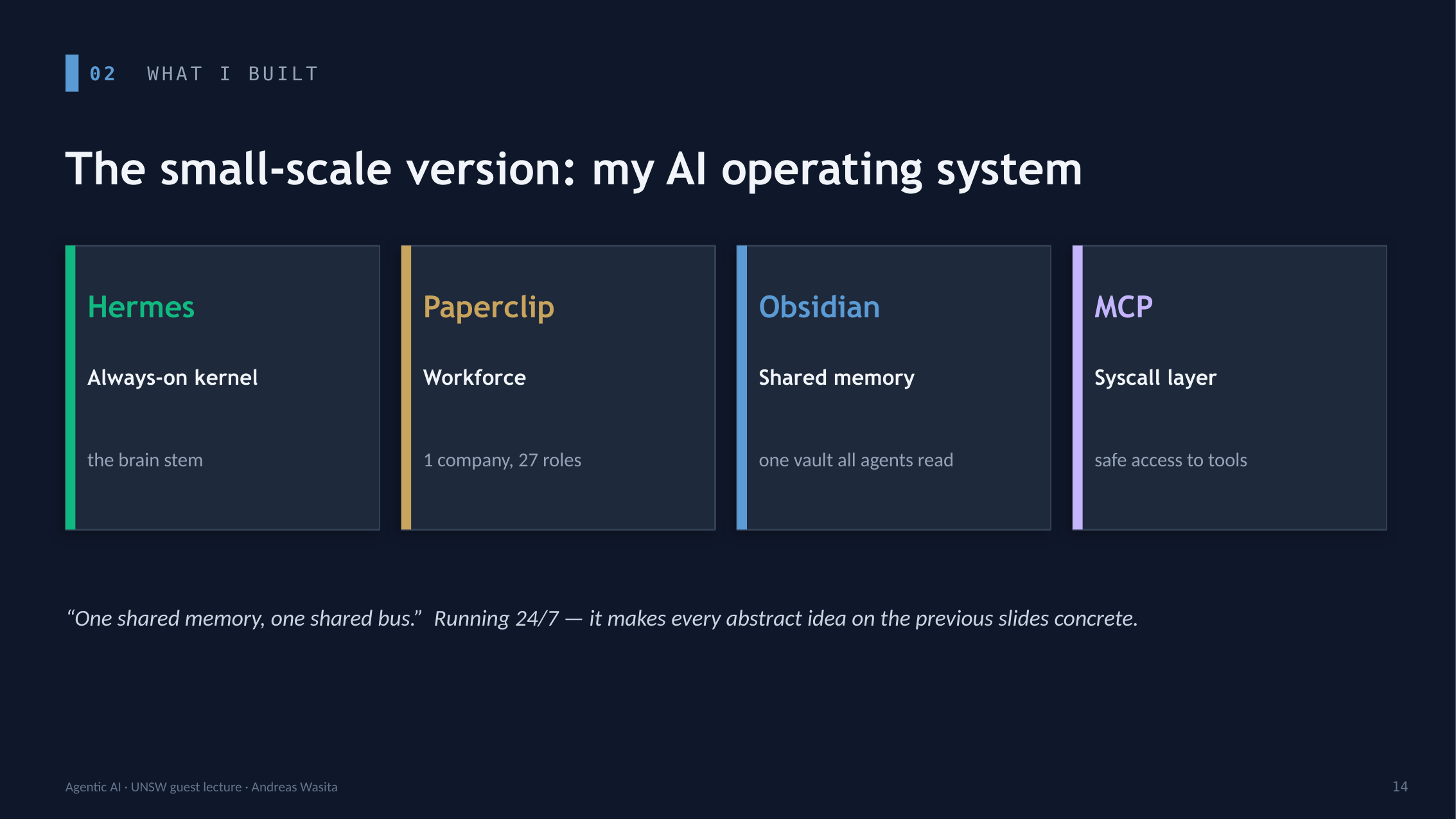
One shared memory, one shared bus. And the part that still unsettles people: the agents learn while I sleep — a nightly loop where they review their own work and write memory updates back into shared memory. Measurably better by morning. But unsupervised learning is just “unsupervised drift with better marketing” unless you add four guardrails: forgetting, identity isolation, a ground source of truth, and a per-identity audit trail. You can sleep. Your agents don’t need to.
Microsoft’s toolset — don’t memorise products, learn three layers
Product names churn. The layers don’t:
- USE — Microsoft 365 Copilot and agents grounded in your data via Graph. Copilot in Word, Outlook, Teams, plus task-specific agents (a student-support agent, a citizen-services agent).
- BUILD — Copilot Studio (low-code maker) and Azure AI Foundry (the pro-code platform: model catalogue, orchestration, Agent Service, evaluation, content safety).
- ENGINEER — frameworks (Semantic Kernel, Agent Framework), the Model Context Protocol, and Purview + Entra for control.
Same agent loop underneath. Choose the layer that matches your team and your stakes.
Where Responsible AI actually lives
This was the question I most wanted the Law and Commerce students to leave with: where in the architecture do you put responsibility? Because “be responsible” on a values slide changes nothing. It has to be a control plane, not an afterthought — wired into specific layers:

- At the data layer — grounding and provenance. The agent answers from your sources, and can show which one. Provenance, or it didn’t happen.
- At the tool layer — least-privilege access, fresh auth on consequential actions, every call logged.
- At the orchestration layer — the human gate on the decision. The clinician signs. The teacher owns the grade. The caseworker decides.
- At the evaluation layer — the done gate. Agents will tell you they finished when they didn’t; completion has to be verified, not narrated.
- Across all of it — a per-identity audit trail, so any action can be explained after the fact.
Speed multiplies whatever you point it at. A chatbot that hallucinates once is an incident. An agent that runs a thousand times a night and learns from its own output can turn one hallucination into a compounding incident. Responsibility doesn’t slow agentic AI down — it’s what makes it shippable. And for this cohort it’s not abstract. Australia already has its AI Ethics Principles, and the government has proposed mandatory guardrails for high-risk AI. These students will be the ones turning that into systems.
What I left them with
The five seminar themes of their course — trust and transparency, accountability, privacy and security, inclusiveness and fairness, resilience and sustainability — map almost one-to-one onto Microsoft’s Responsible AI principles. But the rubric rewards operationalising a principle, not listing it. That’s the same thing as my opening line.
So here’s the sentence I wanted fifty final-year students to carry out of the room:
The demo and the disaster can be the same model. The difference is the system you build around it.
The five green cards weren’t a bad model. They were a missing gate. Go build the gate.
Sources for the figures above: Stanford Medicine on its ambient documentation rollout for the Dragon Copilot deployment and clinician-review workflow (the one-million-note / 1,600-clinician milestone was reported separately by Becker’s Hospital Review, May 2026); the University of Manchester–Microsoft world-first AI partnership for the campus-wide Copilot rollout to ~65,000 students and staff; and the UK Government Microsoft 365 Copilot cross-government experiment findings report for the 20,000-plus staff, ~26 minutes/day saved and 82%-would-not-go-back figures. Provenance, or it didn’t happen.